Contents
Amazon Web Services (AWS) Simple Storage Service (S3) is the most popular way (also the first?) to store data in the cloud. It’s secure by default, however it can be easy to unintentionally expose the data you store in your bucket when you start to change settings and ignore the console warnings. I’m going to go over some of the important steps you should take to help secure your S3 buckets.
Bucket Naming
The first step in S3 security is the name. If you name a bucket companyname-secrets then anyone internal to your organization, and in some circumstances anyone on the internet, can see the bucket exists and may want to see what’s in it. It’s important to know that buckets are normally accessed through an API where the bucket name is resolve by DNS, e.g. bucketname.s3.amazonaws.com so the bucket name could be discovered in DNS logs in your organization or even publicly. There are also tools like bucket-stream and S3Scanner that are designed to enumerate bucket names and do other things all of which breach terms and conditions like the AWS Customer Agreement. My advice is to decide on a bucket name that is globally unique as that is an S3 requirement, is identifiable to its use to only you, but does not give away who it belongs to. For example, if you were storing highly confidential data you could name it data-1-abcdef where data explains use (you could use logs or something else generic of course), 1 is known only by you or your team what it contains, and abcdef is a random code that your team uses to make your bucket unique. You could use the AWS account ID in the bucket name, however I generally recommend against this as it gives away the identifier of your AWS account which could be used for other purposes.
Logging & Monitoring
Requests to S3 buckets at the bucket level, e.g. creating or deleting buckets are included in AWS CloudTrail which you should enable, and have CloudTrail logs located in a separate account for safety. In addition to bucket level actions you should also log actions inside your buckets, e.g. object PUT, GET, and DELETE actions help you trace who or what has accessed (or attempted access) your data. There are two main ways to log in S3; CloudTrail object level logging, and S3 server access logging. CloudTrail logs record the request that was made to S3, IP address, who made the request, date stamp, and some additional details. S3 access logs provide detailed records which may contain additional details to help you with an investigation. I highly recommend you enable at least one of the logging methods, the CloudTrail option is the easiest one to enable.
In addition to logs you should be aware of metrics by setting Amazon CloudWatch alarms to alert you when specific thresholds of request metrics are exceeded. For example, if your bucket is only storing CloudTrail logs then you could set an alarm to alert you of any object DELETE (adversary covering tracks), and a low threshold for PUT and GET. Depending on your support plan you can also use AWS Trusted Advisor’s Amazon S3 bucket permissions check to check for open access permissions.
Amazon GuardDuty is an intelligent threat detection service that you should enable to help detect threats and anomalies, and has S3 protection. S3 protection allows GuardDuty to monitor object level operations to identify potential security risks for data within your S3 buckets. If you have already enabled GuardDuty, go to the console (in each region you have enabled it) and verify you have S3 protection enabled.
Access Analyzer for S3 alerts you to S3 buckets that are configured to allow access to anyone on the internet or other AWS accounts, including AWS accounts outside of your organization. For example, Access Analyzer for S3 might show that a bucket has read or write access provided through a bucket access control list (ACL), a bucket policy, or an access point policy. Access Analyzer for S3 works by first enabling IAM Access Analyzer.
Encryption
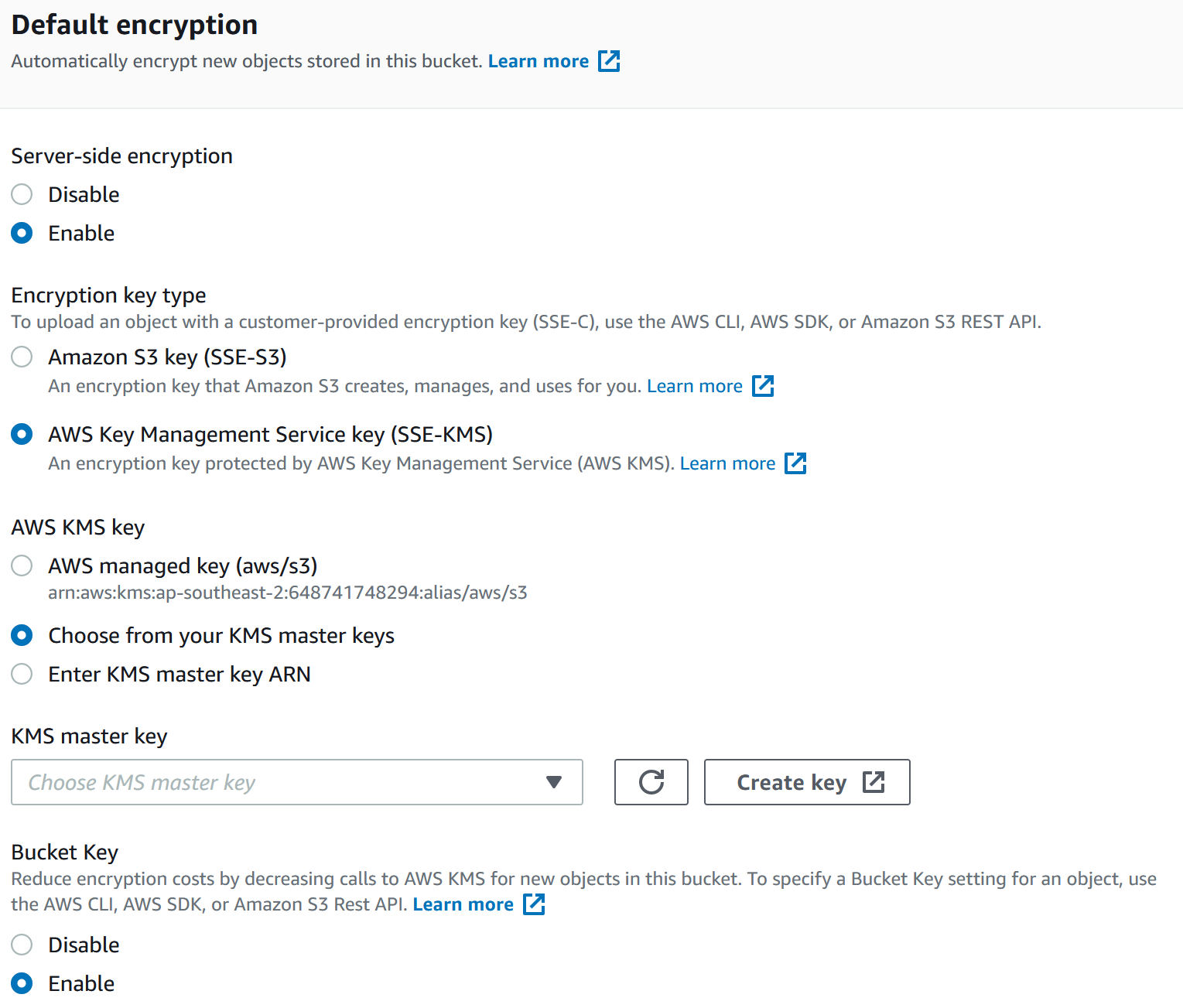
You should enable encryption as it provides an additional layer of security for access control in particular. You control access to your bucket You should always be thinking of defence in depth! There are many encryption options in S3, however the easiest to enable which also happens to be the easiest to use and also very secure is default server-side encryption using KMS. Default encryption works with all new and existing buckets. Without default encryption, you must include encryption information with every object storage request to encrypt objects as they are stored in a bucket. You would also have to set up a bucket policy to reject storage requests that don’t include encryption - see how default encryption is easiest! I highly recommend you look at setting default encryption on all buckets that store sensitive information, test permissions, and be aware that existing objects are not encrypted in place - you would need to PUT them again or some other workaround. When using KMS keys be aware of request quotas and reach out to AWS Support if you need help, if you are under 5,000 requests per second you shouldn’t need to worry. You should consider a separate key for different sensitivity levels of your data, and of course the permissions on the key being different. For example, if you had payroll and customer in different buckets in the same AWS account as they are different types or sensitivity levels you would want to have a separate KMS key for each.
Console for enabling default encryption for a new bucket, note have I’ve selected SSE-KMS and choosing from my own customer key:
Access Control
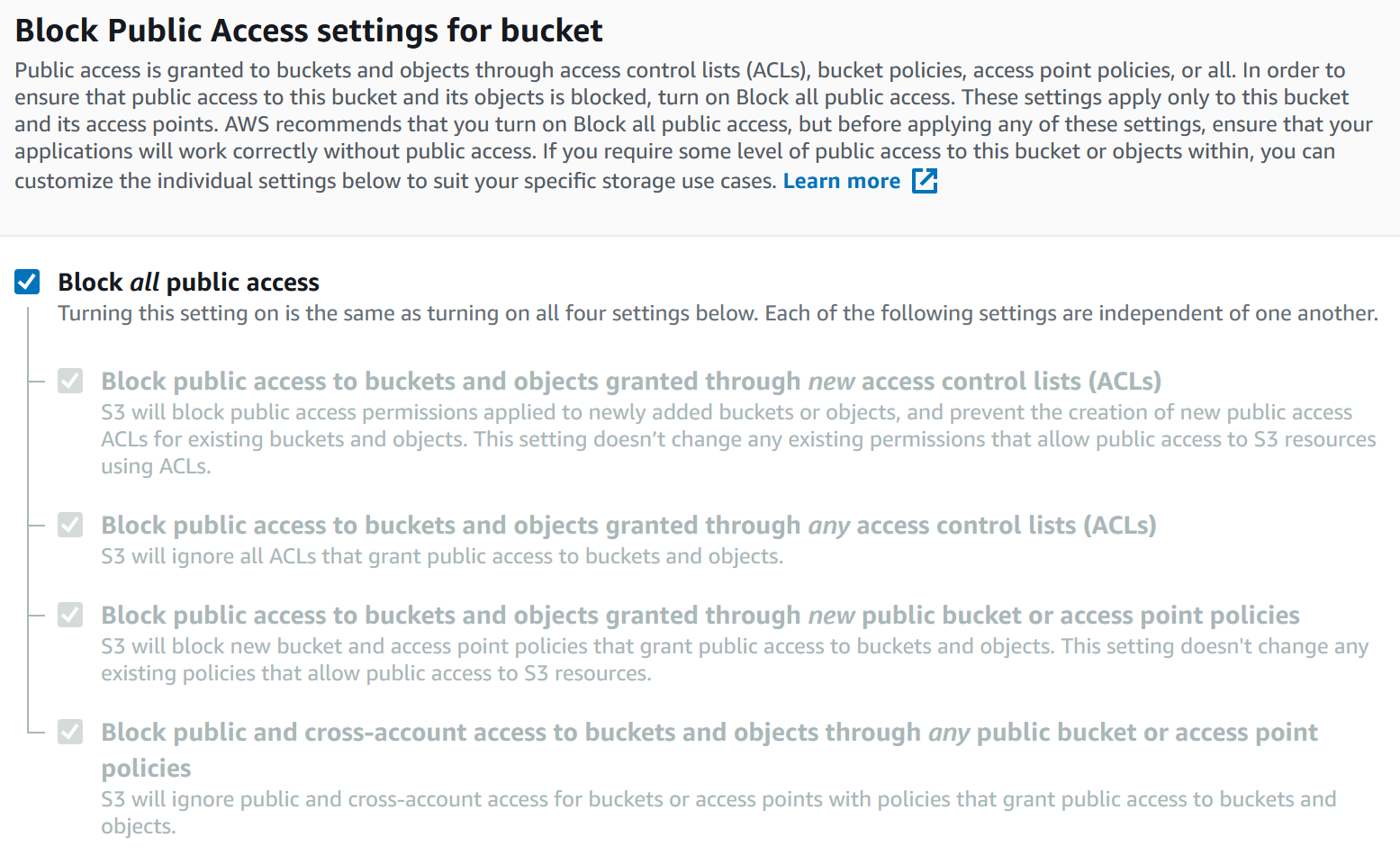
Amazon S3 Block Public Access you can easily set up centralized controls to limit public access to your S3 buckets that are enforced regardless of how they have been created. Amazon S3 considers a bucket or object ACL “public” if it grants any permissions to members of the predefined AllUsers or AuthenticatedUsers groups. When Amazon S3 receives a request to access a bucket or an object, it determines whether the bucket or the bucket owner’s account has a block public access setting applied. If the request was made through an access point, Amazon S3 also checks for block public access settings for the access point. If there is an existing block public access setting that prohibits the requested access, Amazon S3 rejects the request. There are different settings for block public access, I would highly recommend you enable them all, however you might block legitimate access so be careful! You can check for access by looking at the logs for your buckets which I covered earlier.
Console of block all public access options for a new bucket:
Access Control Lists (ACLs) were one of the original ways of granting access to your buckets before IAM existed. They are resource based, which means the resource, in this case the bucket, governs the access - as opposed to an identity based like IAM. When you create a bucket or an object, S3 creates a default ACL that grants the resource owner full control over the resource. You should review the ACLs you have for existing buckets and objects, then I would advise not to use ACLs as it can get confusing. Instead use a bucket policy if you need to grant access to another account, or IAM/SSO if you need to grant access within your account or organization.
AWS Identity and Access Management (IAM) can grant access to S3 buckets from IAM identities including users and roles. An IAM policy can grant access to S3 resources at both the bucket level and object level. When granting access you should have least privilege in mind, does the person or thing really need that access? Can you restrict their access to a single bucket, or even object prefix? You can discover all actions, resources and conditions for S3 in the authorization reference. You can also check out a blog I wrote on Techniques for writing least privilege IAM policies.
MFA Delete has been around for a long time, it adds an additional layer of protection for deleting objects. There is a caveat in enabling, it requires you to log in as the root user. Because of this, and the fact that AWS Organizations created accounts manage the root user for you, I’d recommend you seriously consider other controls first and make your own risk-based decision before enabling.
Bucket policies and user policies grant permission to S3, and are a resource-based policy. I would only recommend using bucket policies when you need to grant permissions to a bucket from another account, where the other account is outside your organization, and access points (see below) do not make sense. For example, in your organization you should be using federation for users, AWS SSO is the easiest way for this, then SSO (using IAM) would grant access to your buckets. Outside of your organization, e.g. a vendor that you need to share data with, you can trust their AWS account (with conditions) to access your bucket following this example.
Access points are named network endpoints that are attached to buckets that you can use to perform S3 object operations, such as GetObject and PutObject. You should look at using access points when sharing data across accounts, instead of bucket policies as they are easier to manage. You can only use access points to perform operations on objects, not bucket operations. Each access point has distinct permissions and network controls that S3 applies for any request that is made through that access point. Each access point enforces a customized access point policy that works in conjunction with the bucket policy that is attached to the underlying bucket. You can configure any access point to accept requests only from a virtual private cloud (VPC) to restrict Amazon S3 data access to a private network. You can also configure custom block public access settings for each access point. Adding an S3 access point to a bucket doesn’t change the bucket’s behaviour when accessed through the existing bucket name or ARN. All existing operations against the bucket will continue to work as before. Restrictions that you include in an access point policy apply only to requests made through that access point.
When to use S3 Access Points is covered in the S3 features, which I’ve directly copied here for reference:
- Large shared data sets: Using Access Points, you can decompose one large bucket policy into separate, discrete access point policies for each application that needs to access the shared data set. This makes it simpler to focus on building the right access policy for an application, while not having to worry about disrupting what any other application is doing within the shared data set.
- Restrict access to VPC: An S3 Access Point can limit all S3 storage access to happen from a Virtual Private Cloud (VPC). You can also create a Service Control Policy (SCP) and require that all access points be restricted to a Virtual Private Cloud (VPC), firewalling your data to within your private networks.
- ** Test new access policies:** Using access points you can easily test new access control policies before migrating applications to the access point, or copying the policy to an existing access point.
- Limit access to specific account IDs: With S3 Access Points you can specify VPC Endpoint policies that permit access only to access points (and thus buckets) owned by specific account IDs. This simplifies the creation of access policies that permit access to buckets within the same account, while rejecting any other S3 access via the VPC Endpoint.
- Provide a unique name: S3 Access points allow you to specify any name that is unique within the account and region. For example, you can now have a “test” access point in every account and region.
Safety
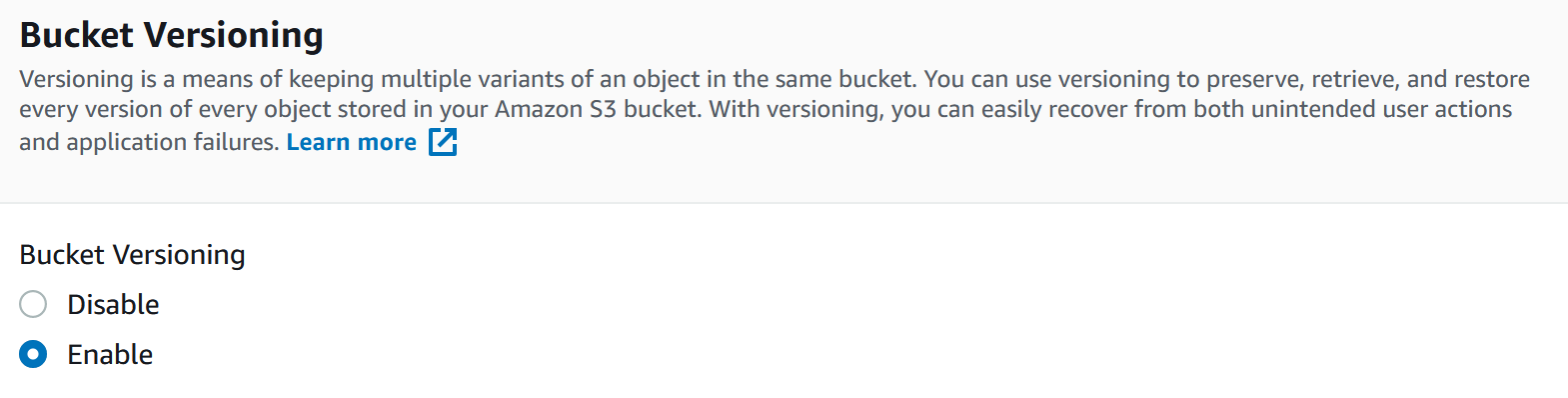
Bucket versioning allows the automatic creation of multiple versions of an object. When an object is deleted with versioning turned on, it is only marked as deleted but is still retrievable. If an object is overwritten, previous versions are stored and marked. From a security perspective it’s highly recommended you enable versioning as it provides safety against accidental or malicious tampering or removal of data. The permissions for S3 are separated between manipulating objects and object versions. For example, the DeleteObject action is different to DeleteObjectVersion. This means you can grant only DeleteObject permission which inserts the delete marker, but the versions of the object cannot be touched.
S3 Object Lock is an option you can enable to prevent objects from being deleted or overwritten for a fixed amount of time. It’s a model like write-once-read-many (WORM) and has been assessed by various regulations for safeguarding your data. You should make your own risk-based decision to enable it or not. You can simply create a new bucket following the previous best practices, enable object lock (under advanced settings), then apply a retention period and/or legal hold settings on the objects to protect (or the entire bucket).
Amazon Macie is a managed data security and privacy service that uses machine learning and pattern matching to discover and protect your sensitive data in S3. It’s value is in discovering the data you are storing, for example it can detect credit card numbers in objects stored in your buckets - did you know they were there? I would recommend you use the 30 day free trial and see what it can do for you.
Bucket Policy Tricks
There is a trick that I’ve used to completely “lock” a bucket, including the ability to unlock it. You see in AWS explicitly denying something, like access to a bucket in a bucket policy, will rule over any allow permission anywhere else, even IAM. This means you can use a bucket policy to deny deleting objects or object versions, even modifying the bucket policy itself. The only way to remove this bucket policy is to log in as the AWS root user for the account. If the account is managed by an AWS Organization, and not the management account, you can even block logging in as the root user. In fact if you created the account in Organizations then there is a special process you need to go through to even log in as the root user. I’d share the policy with you but it’s too dangerous. You can find out a safer example to implement in premium support knowledge center.
Further reading:
AWS Well-Architected Security Pillar
Official Security Best Practices for Amazon S3